Table of Contents
- Why Data Quality Matters
- Key Dimensions of Data Quality
- Categories of Data Quality Issues
- 1. Completeness
- 2. Consistency
- 3. Accuracy
- 4. Timeliness
- 5. Validity
- 6. Uniqueness
- 7. Integrity
- Causes and Impacts of Bad Data Quality
- Common Causes
- Additional Challenges in Modern Systems
- Ensuring Data Quality
- a. Data Validation and Cleaning
- b. Data Governance Framework
- c. Continuous Monitoring
- d. Six Sigma methodologies
- e. Collaboration among teams
- Ethics and the Lifecycle of Data
- Conclusion
- References
.png?table=block&id=18358e34-9680-80e5-a1cb-c66f6bc76641&cache=v2)
Do not index
Canonical URL
Back in 2017, The Economist declared that "the world's most valuable resource is no longer oil, but data." Similarly to oil, data's value does not derive from its raw state; it must be properly preserved, cleaned, and refined before it can be used.
And, just as contaminants in oil make it difficult to use, bad data can degrade analytics, impair machine learning models, and undermine customer trust. Maintaining high-quality data is not only a technical requirement but also a strategic imperative for businesses seeking to remain competitive in today's data-driven economy.
Why Data Quality Matters
According to Statista, the total volume of data created, captured, copied, and consumed worldwide is expected to skyrocket, reaching 149 zettabytes by the end of 2024—that's 149 followed by 21 zeros! 🤯
In recent years, the perception of data has actually evolved from the analogy of "data is the new oil." Unlike oil, which is a finite resource that diminishes in value after use, data is infinitely durable and can be reused and repurposed without losing its utility.
Therefore, data quality not only improves analytics and machine learning models, but it also increases confidence within businesses. According to a snapLogic study, 91% of IT decision-makers say their company's data quality has to be improved, and 77% believe their organization's business data is untrustworthy.
Dataset inaccuracies also have an impact on artificial intelligence and machine learning systems. These models are quite sensitive to the quality of the input data. Even the most advanced algorithms will fail if the data is of poor quality. If the data is biased, incomplete, or out of date, the models may make incorrect predictions or reinforce systemic biases. Stanley and Schwartz (2024) caution that artificial intelligence (AI) enhances the strengths and weaknesses of data, thereby increasing the risks for companies that depend on predictive systems.
Have you heard about the "butterfly effect"? That is a concept popularized by mathematician Edward Lorenz that suggests a small change, such as the flap of a butterfly's wings, can trigger a cascade of events leading to large-scale outcomes.
Minor flaws, missing numbers, or inconsistent formats of data can spread throughout networked systems, multiplying errors and compromising decision-making processes. These difficulties can originate from ordinary occurrences such as manual entry errors or antiquated technology, but the implications, which range from inaccurate analytics to regulatory noncompliance, can be chaotic.
For all these reasons, clean, representative, and ethical data should be non-negotiable. And Data Scientists are tasked with turning raw, messy data into something actionable. This involves, I’d say, a blend of detective work, standardization, and critical thinking to ensure accurate insights—because in the end, the raw potential of data means nothing without the effort to refine and validate it.
Put simply, organizations can fully utilize their data, build robust models, foster innovation, and maintain stakeholder trust by prioritizing data quality.
To ensure that your data is as trustworthy as your decisions, we will address the importance of data quality in this blog, as well as its dimensions, typical hazards, and solutions for assuring trustworthy data in machine learning and analytics systems.
High-quality data is the foundation of informed decision-making, trustworthy models, and meaningful progress.
Key Dimensions of Data Quality
In a world where organizations generate and consume massive volumes of data, it is truly impossible to overestimate the significance of data quality. Businesses use it to guide everything from customer interactions to product development.
Data quality is the foundation for analytics and machine learning. It assures that the data we use is correct, comprehensive, consistent, relevant, and legitimate for the questions we intend to answer.
But beneath the surface, there lies a concerning truth: a large portion of this data is faulty. Unfortunately, messy datasets are the norm rather than the exception.
However, when handled with care, data quality empowers analysts and machine learning practitioners to ask better questions, reveal hidden patterns, and make decisions with confidence.

Categories of Data Quality Issues
Ensuring high-quality data is a difficult challenge that needs a thorough understanding of all essential variables. So, effective data management begins with a grasp of the important dimensions of data quality.
Drawing on findings from [2] Stanley and Schwartz (2024), we can break down data quality into six important aspects that illustrate the issues businesses face and the areas where monitoring can have the biggest influence.
1. Completeness
Completeness assesses whether all necessary data is included in a dataset. Missing data or rows can make models unproductive or biased, especially if essential characteristics are lacking.
- Example: Due to limits in Microsoft Excel's row capacity, roughly 15,841 positive COVID-19 test results were omitted from official records. Because of this omission, a considerable number of positive cases were unreported, resulting in insufficient data and potentially impeding public health actions.
2. Consistency
Consistency ensures that data remains uniform across systems, databases, and time periods. Inconsistent data formats or definitions might cause problems during preprocessing and training.
- Example: In a supply chain system, one database may use "CA" as the state abbreviation for California, while another spells it out as "California." This inconsistency could lead to duplicate entries and mistakes in predicted demand models.
3. Accuracy
Accuracy relates to how well the data matches real-world values, or the "ground truth." Inaccurate data in machine learning can result in incorrect predictions, decreased trust in the model, and even operational concerns.
- Example: One significant example is Equifax’s credit score miscalculation during a cloud migration in 2022. This miscalculation affected 12% of credit scores, resulting in overestimated lending rates and refused mortgage applications.
4. Timeliness
Timeliness refers to how up-to-date and accessible information is when needed. Machine learning models trained on obsolete data may struggle to generalize successfully in dynamic situations.
- Example: For an e-commerce recommendation engine, using two-month-old sales data, for example, may fail to reflect recent purchasing trends, limiting suggestion efficacy.
5. Validity
Validity determines whether the data follows the appropriate formats, standards, or limitations. This level frequently includes verification for syntactical accuracy during data intake.
- Example: Migrating data from legacy systems to modern cloud warehouses frequently causes validity difficulties. For example, in a date field with the format YYYY-MM-DD, a record with 2024-13-12 would break this restriction, potentially triggering downstream difficulties in ML pipelines.
6. Uniqueness
Uniqueness assures that the dataset has no duplicate records. Duplicates can affect model training by overrepresenting specific patterns, resulting in bias.
- Example: A customer churn prediction model trained on a CRM dataset including duplicate entries for the same customer may produce falsely exaggerated churn rates, leading to inaccurate business decisions.
7. Integrity
Integrity refers to the maintenance of accurate relationships between data elements, as well as the preservation of dependencies and connections. Without integrity, downstream apps or analytics may generate erroneous or incomplete results.
- Example: Foreign key violations can break client ID-transaction record links in relational databases. Analytics systems may not report transactions if a customer ID in the transaction table does not match a customer entry in the customer table, resulting in incomplete revenue estimates or inaccurate predictions.
While all of these factors determine data quality, their value varies depending on the context or application. Understanding the interactions between these characteristics is crucial for creating resilient, ethical, and successful data systems.
Our conclusions are only as strong as the data behind them.
Causes and Impacts of Bad Data Quality
Unlike software bugs, which are frequently isolated and resolved, data quality is a moving target because data is dynamic; external factors such as user behavior, market changes, and third-party integrations all have an impact on its quality. It is also influenced by internal changes such as system migrations, feature enhancements, and organizational expansion.
Common Causes
Bad data may enter systems for a variety of causes. Understanding the causes of bad data and its impacts is critical for addressing these challenges effectively. According to Mahanti (2019), common causes are:

Additional Challenges in Modern Systems
As highlighted by Stanley & Schwartz (2024), modern data ecosystems introduce additional complexities:
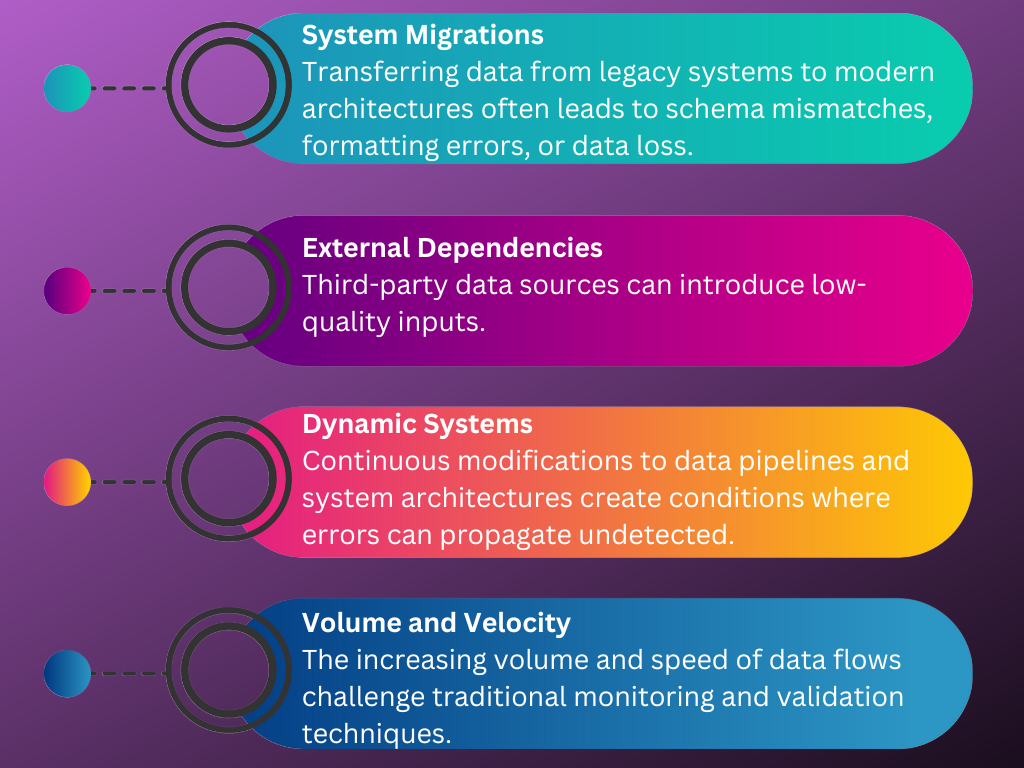
Long story short, the consequences of poor data quality are far-reaching, affecting every stage of analytics and decision-making. Organizations face operational inefficiencies, reduced trust in analytics, and increased risks of regulatory noncompliance. Moreover, bad data undermines machine learning models, leading to inaccurate predictions and poor business outcomes.
Without quality in all aspects, data is a liability rather than an asset, resulting in erroneous insights and missed opportunities.
Ensuring Data Quality
The challenge lies in the fact that most data quality issues remain silent, gradually eroding the value of the company. Issues can show up as deceptive dashboards, poor AI models, or incorrect analytics that lead decision-makers astray. When data-driven systems fail to deliver accurate, timely, or tailored experiences, the consequences extend beyond operations to customers.

Therefore, businesses should employ a number of best practices to ensure clean, high-quality data, such as:
a. Data Validation and Cleaning
Implement strict validation standards and automated purification methods at each stage of the data flow. This guarantees that incorrect, incomplete, or duplicate records are recognized and repaired in a timely manner.
b. Data Governance Framework
A strong governance approach establishes clear ownership, accountability, and data-management norms. Governance for machine learning systems comprises monitoring data inputs, creating quality measures, and keeping audit trails.
c. Continuous Monitoring
Integrating continuous data monitoring into machine learning pipelines allows for the real-time detection of anomalies or quality degradation. Monitoring solutions can send out notifications when data falls below established quality limits, allowing teams to respond promptly.
d. Six Sigma methodologies
ML teams can employ process improvement strategies like as Six Sigma DMAIC (Define, Measure, Analyze, Improve, Control) to methodically address data quality concerns, concentrating on root causes rather than short remedies.
e. Collaboration among teams
Ensuring data quality is a cross-functional task. Data scientists, engineers, and business teams must work together to align data quality objectives with ML performance needs.
Data quality needs to be addressed proactively rather than reactively.
Ethics and the Lifecycle of Data
Finally, data quality encompasses data ethics and privacy. Today, much of the data we collect—email addresses, phone numbers, medical records—is considered personally identifiable information (PII). Ethical data practices require us to respect ownership, obtain informed consent, and protect privacy.

As highlighted in a Forbes article, organizations face significant challenges in this area, including increased customer awareness, increased regulatory scrutiny, and a shortage of trained data specialists.
Data ethics is inextricably linked with quality throughout the data lifecycle:
- Collection: Are persons informed, and do they consent to the use of their personal information? Are you responsible for managing live, dynamic, or static data sources?
- Storage and security: How is sensitive PII protected?
- Analysis: Are biases identified and addressed, and are the results fair and equitable?
- Communication: Are the findings conveyed in a clear, actionable, and honest manner?
When we fail to address these concerns, we risk serious consequences. Misused or misunderstood data can cause serious harm. Consumers are becoming more aware of how their data is gathered, stored, and used. According to a KPMG survey from 2021, 30% of consumers are unwilling to disclose their data under any circumstances, and around 75% want more openness about how it is used. This trend requires firms to emphasize data privacy and transparency in order to maintain customer trust.
The regulatory landscape is also changing, with regulations such as the General Data Protection Regulation (GDPR) in the EU and the California Consumer Privacy Act (CCPA) in the United States setting strict standards on data processing procedures. Noncompliance can result in serious penalties, making it critical for enterprises to remain on top of these requirements and create strong data governance structures.
Furthermore, there is a significant deficit in data skills within the workforce. A reserach by Tableau found that while data volumes are predicted to double by 2026, the number of data experts does not keep up. This gap highlights the need for organizations to invest in comprehensive data literacy and training programs to provide their staff with the skills required to manage data ethically and successfully.
It is critical to include these concerns in your data quality plan. Organizations may guarantee that their data practices are not only compliant but also ethical and in line with best practices in data management by addressing customer concerns, following regulatory standards, and bridging the data skills gap.
Data ethics demand anonymity, informed permission, and ownership.
Conclusion
As data ecosystems become more complex, investing in effective data quality measures becomes critical to long-term success. Understanding the aspects of data quality, addressing common problems, and implementing successful solutions will assist businesses in laying the groundwork for trust and reliability, which will fuel innovation.
Any successful data-driven endeavor requires high-quality data. Poor-quality data can lead to costly errors, betrayals of trust, and missed opportunities, whether through missing records, incorrect entries, or data that simply does not follow business logic.
Businesses that invest in automated and scalable data quality solutions maximize the value of their data while avoiding inconsistency and inaccuracies. In this environment, data quality is not just a technical challenge; it is a strategic advantage.
Do you need help checking the quality of your data? Contact us to find out how our tools can provide clear, trustworthy, and actionable information for your models.
References
[1] Mahanti, R. (2019). Data quality: Dimensions, measurement, strategy, management, and governance. ASQ Quality Press.
[3] https://www.statista.com/statistics/871513/worldwide-data-created/
[4] https://www.economist.com/leaders/2017/05/06/the-worlds-most-valuable-resource-is-no-longer-oil-but-data
[5] https://www.theguardian.com/politics/2020/oct/05/how-excel-may-have-caused-loss-of-16000-covid-tests-in-england
[6] https://edition.cnn.com/2022/08/03/business/equifax-wrong-credit-scores/index.html
[7] https://www.forbes.com/sites/tableau/2022/11/21/with-great-data-comes-great-responsibility/
Written by
