
Do not index
Canonical URL
Standard metrics like precision and recall can feel limiting in the context of predictive maintenance. These models deal with complex, imbalanced datasets where failures are rare but expensive, and false alarms are costly.
Most of the time, relying on traditional metrics doesn’t capture the true financial impact of predictions like preventing a machine breakdown or optimizing maintenance schedules.
How do you know whether your model is truly reducing costs, saving time, or improving maintenance efficiency?
In this blog post, you’ll learn how to craft classification metrics that not only reflect model performance but also connect directly to business outcomes.
The ML Use Case at Hand
I developed a predictive maintenance model using a Gradient Boosting Classifier to identify potential machine failures in a milling process. The dataset is a synthetic representation of 14 features and 10,000 rows, simulating the typical operation of a milling machine. These features include machine vibration, temperature, rotation speed, and torque, which collectively provide a comprehensive view of the machine's condition during operation.
For a data scientist, these features open up numerous possibilities to explore custom metrics tailored to the specific nuances of predictive maintenance.
Only Two Python Functions
NannyML Cloud allows you to add custom metrics with just two Python functions: the
calculate function and the optional estimate function.The first function,
calculate, is mandatory and serves as the foundation for evaluating your custom metric. If you have ground truth data available, calculate will assess how well your model performed by comparing its predictions to actual outcomes.Without ground truth data to validate predictions, it becomes difficult to determine whether a machine would have failed had no maintenance been performed or whether a prediction of continued operation is correct.
The
estimate function comes into play when ground truth is missing or delayed. It can provide an approximation of performance based on calibrated probabilities, ensuring that you can monitor your model even without real-time labels.These calibrated probabilities are generated by NannyML from the model's predictions.
Whether you have access to true target values or need to estimate performance, you have everything you need to track your model's impact.
Matthews Correlation Coefficient
The Matthews Correlation Coefficient (MCC) is a solid choice for evaluating predictive maintenance models, like the one we've built for the milling machine.
It’s especially useful when your dataset is unbalanced, which is often the case in predictive maintenance.
Here is the code for calculate and estimate function:
from sklearn.metrics import matthews_corrcoef
import numpy as np
import pandas as pd
def calculate(
y_true: pd.Series,
y_pred: pd.Series,
**kwargs
) -> float:
y_true = y_true.astype(int)
y_pred = y_pred.astype(int)
return matthews_corrcoef(y_true, y_pred)
import numpy as np
import pandas as pd
def estimate(
estimated_target_probabilities: pd.DataFrame,
y_pred: pd.Series,
**kwargs
) -> float:
y_pred = np.asarray(y_pred)
estimated_target_probabilities = estimated_target_probabilities.to_numpy().ravel(
data = pd.DataFrame({
'estimated_target_probabilities': estimated_target_probabilities,
'y_pred': y_pred
})
data.dropna(axis=0, inplace=True)
estimated_target_probabilities = data['estimated_target_probabilities'].to_numpy()
y_pred = data['y_pred'].astype(int).to_numpy()
# Calculate estimated confusion matrix elements
tp = np.sum(np.where(y_pred == 1, estimated_target_probabilities, 0))
fp = np.sum(np.where(y_pred == 1, 1 - estimated_target_probabilities, 0))
fn = np.sum(np.where(y_pred == 0, estimated_target_probabilities, 0))
tn = np.sum(np.where(y_pred == 0, 1 - estimated_target_probabilities, 0))
numerator = (tp * tn) - (fp * fn)
denominator = np.sqrt(
(tp + fp) * (tp + fn) * (tn + fp) * (tn + fn)
)
if denominator == 0:
return 1
mcc_estimated = numerator / denominator
return np.nan_to_num(mcc_estimated)
We’ve created a range of resources to support you as you add these Python functions and metrics to the dashboard.Check out our documentation for detailed steps, explore our blog post for a full walk-through, or watch our webinar to see it all in action.

On adding the metric correctly in the dashboard, the metric will be displayed like so on the Performance page:
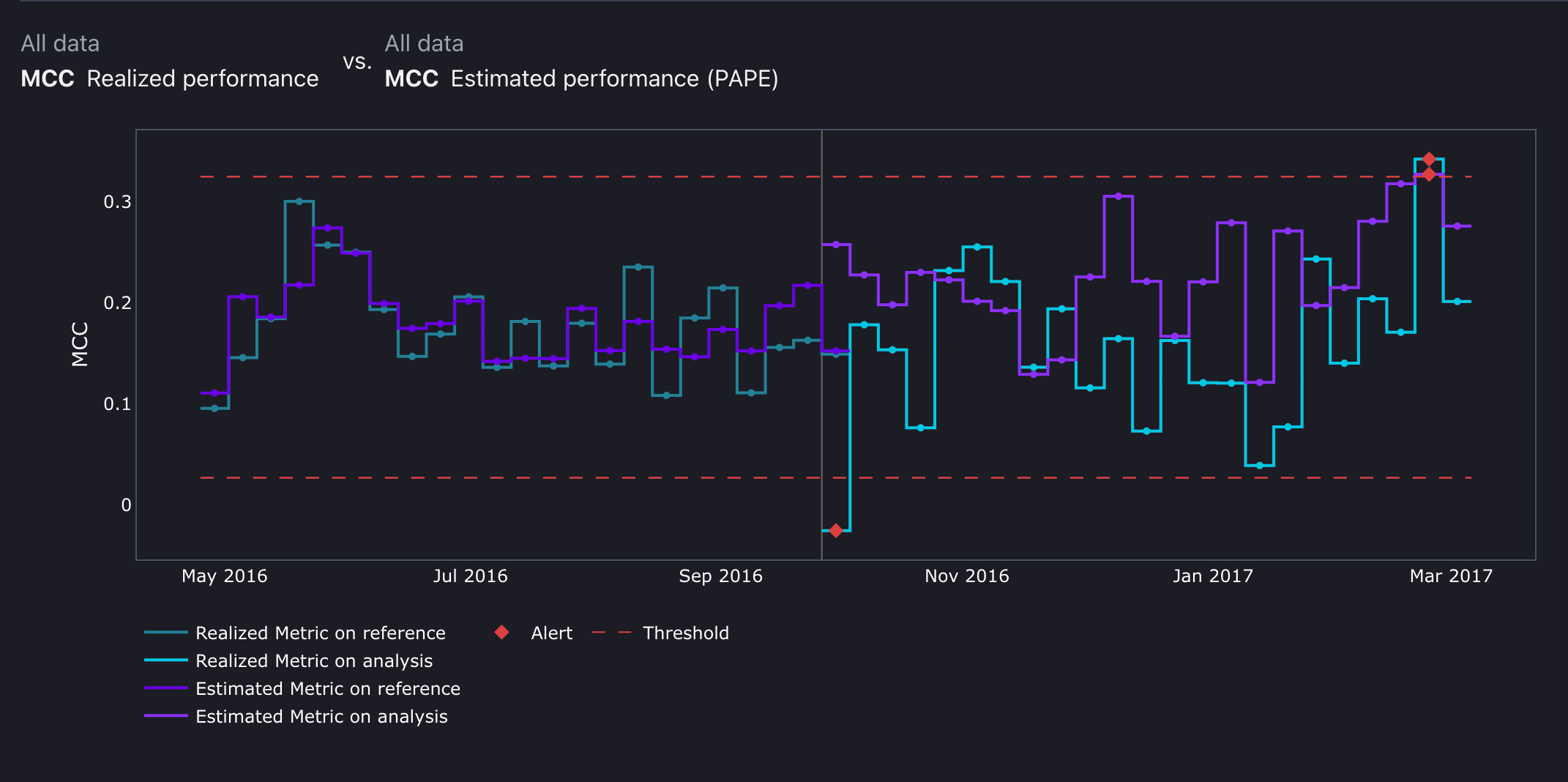
This formula gives a value between -1 and 1, where 1 represents a perfect prediction, 0 is equivalent to random guessing, and -1 indicates a completely wrong model.
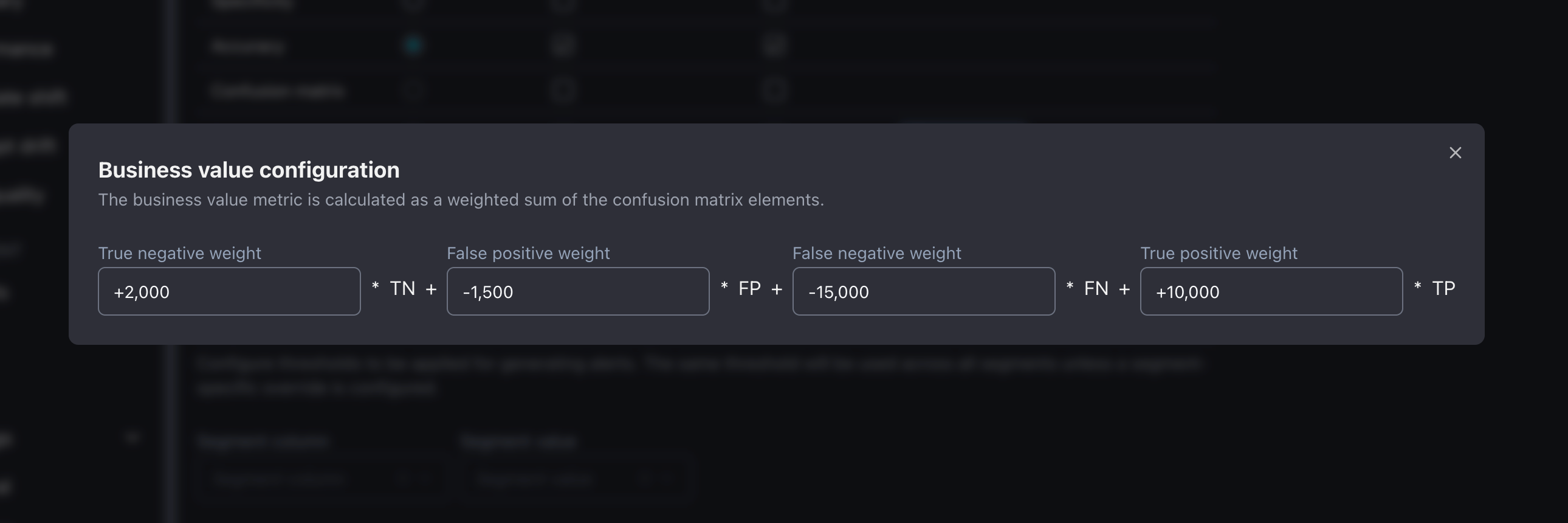
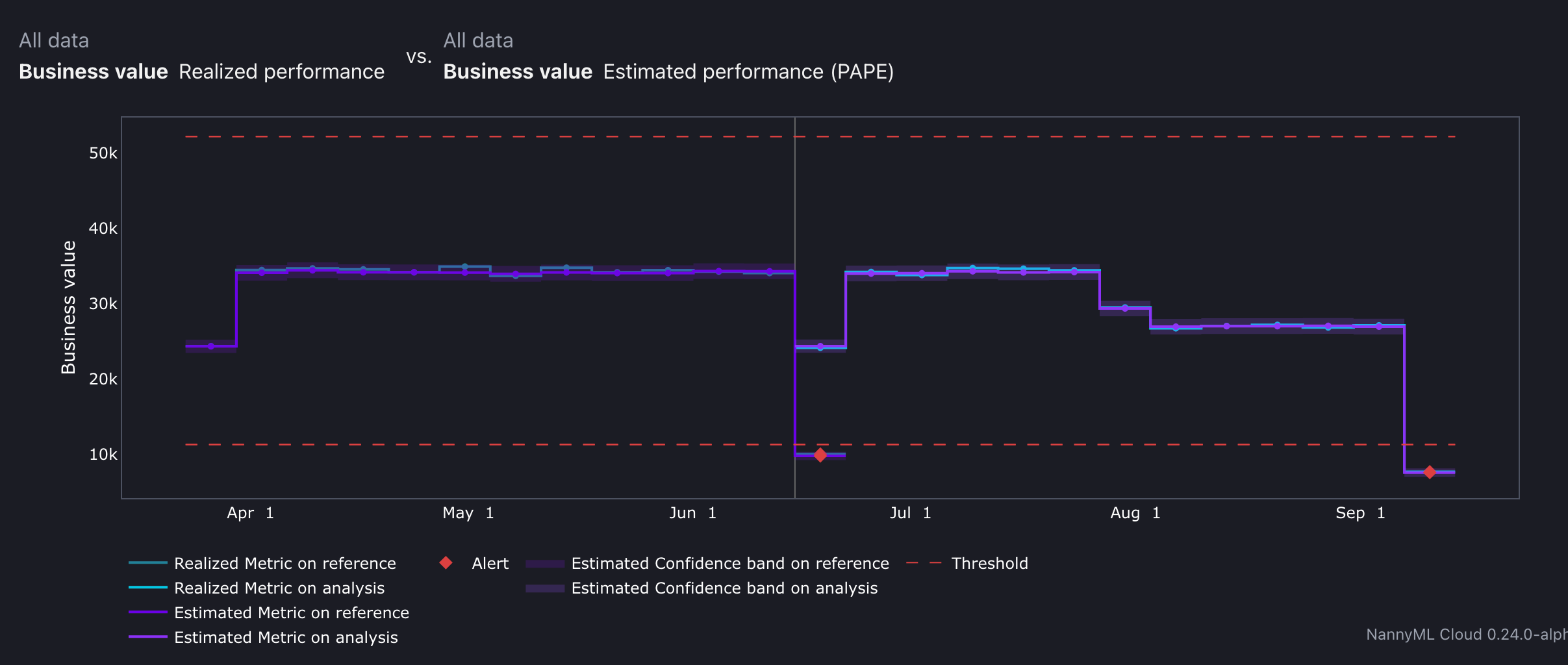
Business Value Metric
The Business Value Metric is useful when communicating with non-technical stakeholders because it translates technical performance into direct financial impact.
Here is how I configured it for this model:
The metric will be visualised as follows:
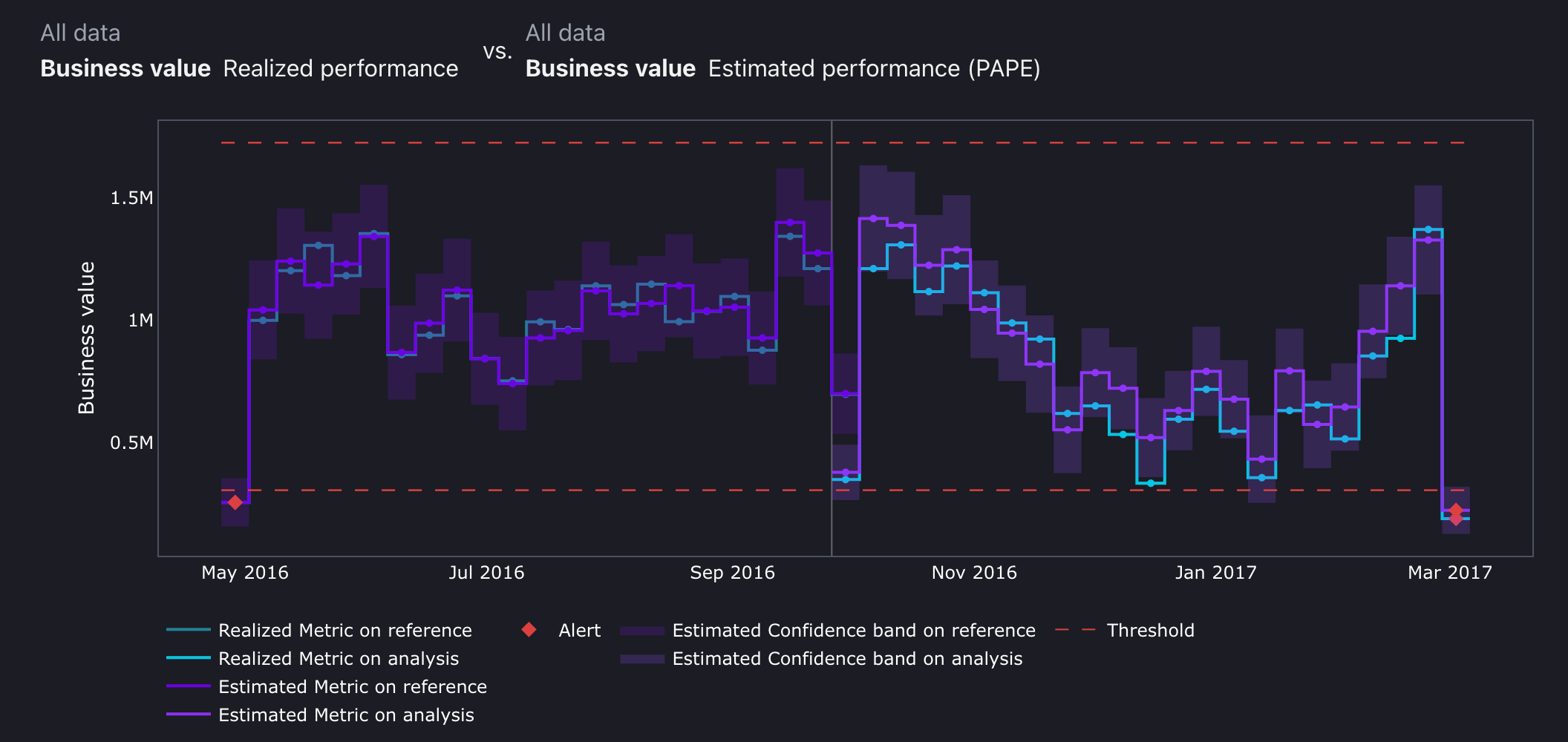
When ground truth labels are unavailable, NannyML offers performance estimation algorithms, which estimate the confusion matrix and apply the same business value formula to approximate the model’s financial impact.
This metric is also available for multi-class models.
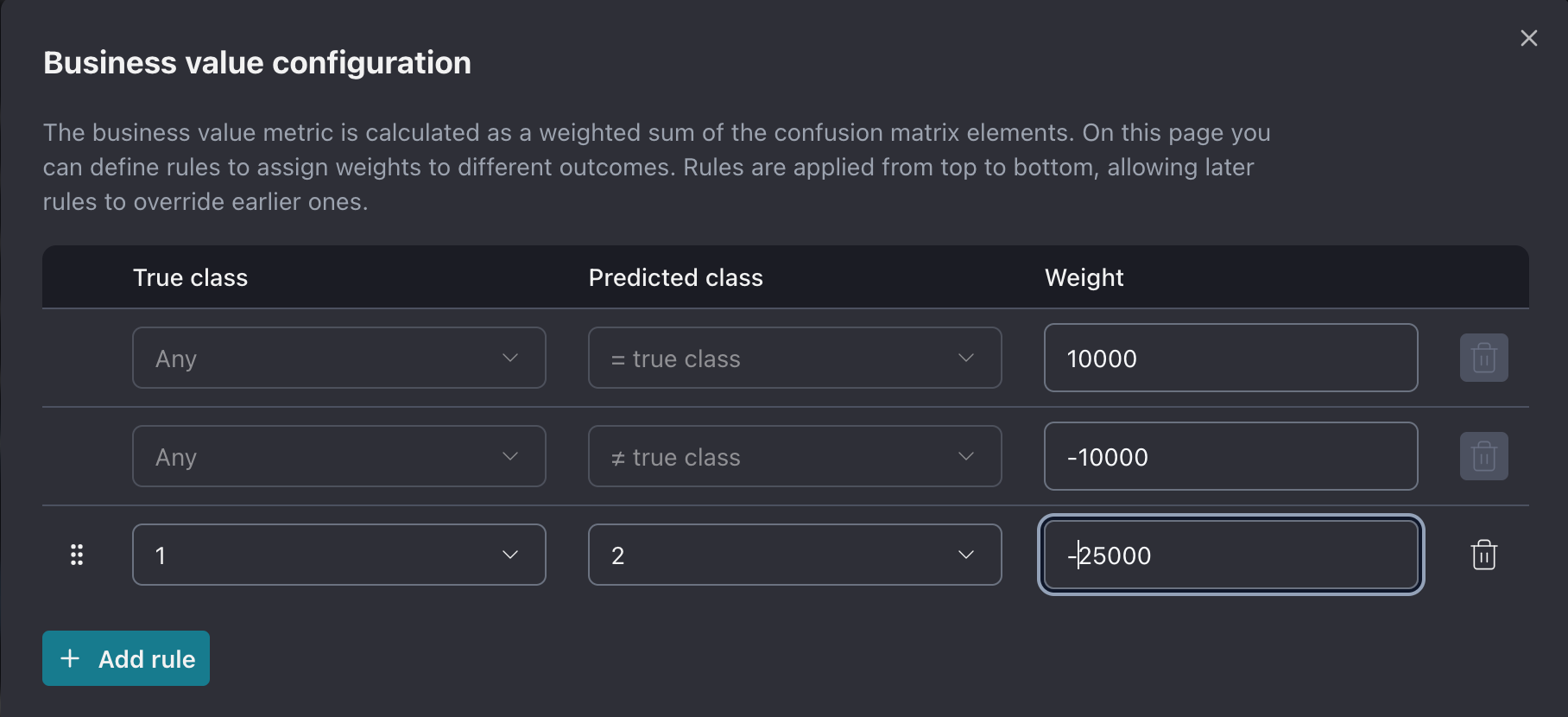
In the above image, the first two rows are default rules that cannot be removed; you can only change the weights. The first row is essentially “correct prediction” whereas the second row is “incorrect prediction”.
All the rows after that allow you to configure overrides, say a correct prediction for a specific class has higher value, you can add a rule for that with the appropriate weight.
These rules are applied from top to bottom without any checks on duplicate rows.
In the dataset, the shilling machine had five independent failure modes: tool wear failure, heat dissipation failure, power failure, overstrain failure, and random failure.
Misclassifying tool wear failure as a heat dissipation issue wastes time and effort spent troubleshooting the wrong problem and therefore doubling both the time required and technician costs. The weight of every correct and incorrect classification should be determined with your team.
Conclusion
In this blog, we covered how to create and add custom metrics to your model monitoring workflow.
We looked at metrics like the Matthews Correlation Coefficient and business value estimation. These metrics help you communicate clearly with stakeholders and show the financial impact of predictive maintenance.
At NannyML, we know that each use case brings unique challenges. If you're facing specific hurdles with model monitoring, consider scheduling a demo with our founders. They’re here to discuss your needs and help you get the best out of your data science solutions.
Read More…
Looking for more custom metrics?






If you’re interested in learning how to maintain and monitor ML models in manufacturing, take a look at my other blogs.




References
The dataset used in the blog is part of the following publication: S. Matzka, "Explainable Artificial Intelligence for Predictive Maintenance Applications," 2020 Third International Conference on Artificial Intelligence for Industries (AI4I), 2020, pp. 69-74, doi: 10.1109/AI4I49448.2020.00023.
Written by
